 fk0легенда (25.05.2018 12:58, просмотров: 241) ответил lloyd на PDM-демодуляторы стоят довольно во многих (не-массовых) МК. Есть у MSP430, новых C2000, у STM32, у Infineon (из тех, что я знаю).
fk0легенда (25.05.2018 12:58, просмотров: 241) ответил lloyd на PDM-демодуляторы стоят довольно во многих (не-массовых) МК. Есть у MSP430, новых C2000, у STM32, у Infineon (из тех, что я знаю).
Да вообще подход к задаче в стиле Евгения-CD -- поставим большую wunderwaffe и она сама непонятно как всё сделает. Не нужны здесь wundervaffe, ибо ряд ньюансов: во-первых восприятие с каждого микрофона не обязано быть непрерывным, ведь и видео это набор дискретных кадров, и обсчёт сигнала тоже ведётся на дискретных временных интервалах, а не непрерывно.
Отсутствие непрерывности позволяет быстро свалить данные в память и медленно вычитать и обработать. Это ключевой момент. Второй ключевой момент, что данные цифровых микрофонов прекрасно мультиплексируются по-времени и из 100 параллельных потоков можно получить один в 100 раз более быстрый последовательный. Это тоже принципиальный момент, потому, что тех же декодеров нужно в 100 раз меньше и всей прочей логики. Но декодер не может работать с мультиплексированным потоком как есть, он же является, условно, автоматом с памятью, и ему для каждого потока своя память нужна. Поэтому если запись с микрофонов ведётся строго последовательно (1,2,3,4...99,100,1,2,3...) и в таком виде поступают биты, то потом данные должны быть сложены в память и прочитаны в переупорядоченном виде (1,2...99, 1,2,3...99...) -- сигнал каждого микрофона непрерывно. И в таком виде могут быть отправлены на единственный PDM-декодер (который уже начинает вмещаться в ПЛИС, потому, что он один). И далее на CPU для обработки. Причём декодер может быть не полноценным, а включать в себя только фазу уменьшающую число бит до разумной величины, дальше возможна постобработка на CPU.
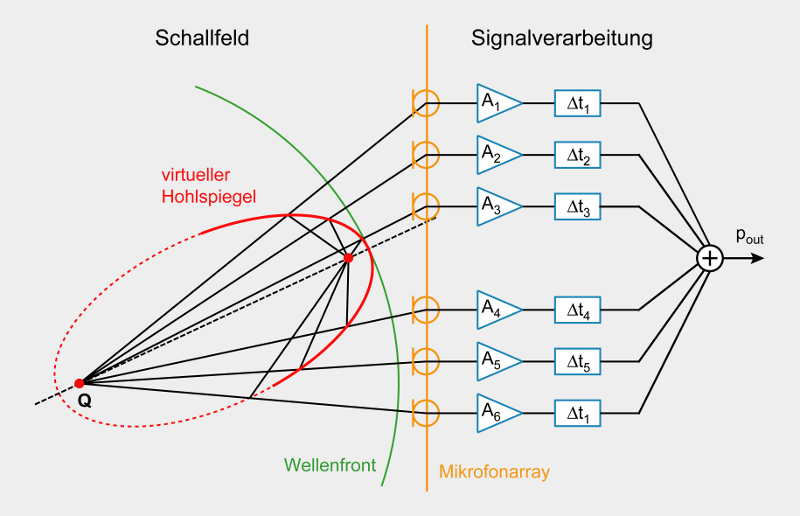
Обработка заключается в том, N раз в секунду данные с массива микрофонов преобразуются в картинку, накладываемую поверх видео. Формирование картинки осуществляется таким образом, что для каждого пикселя (их, примерно, 100x100 для видео-кадра) формируется диаграмма направленности микрофонного массива так, чтоб он смотрел в нужное место и входной массив сырых данных обсчитывается заново, полученная амплитуда формирует яркость или цвет пикселя. Обсчёт массива заключается в суммировании сигналов с каждого микрофона, каждый со своим коэффициентом усиления и каждый со своим коэффициентом задержки (именно эти два коэффициента формируют диаграмму направленности, "beam forming"). Тут, кажется, тоже есть место для ПЛИС... хотя CPU с зачатками DSP справится не хуже (нужен MAC).
Сколько нужно памяти. Допустим кадр формируется 4 разa в секунду и состоит из фрагмента записи длиной 20мс (что даёт нижнюю частоту в 50Гц). Допустим биты с каждого микрофона идут на частоте 2 МГц. Итого 40 килобит на 100 микрофонов -- на "кадр" нужно всего-то 0.5 МБайта памяти, которые должны быть записаны за 20мс со скоростью 12.5 миллионов слов (16 бит) в секунду. Вполне доступно для современных микросхем SRAM. ПЛИС может последовательно брать бит с каждого микрофона и формировать параллельно записываемые в последовательно идущие ячейки памяти слова. Потом можно уже не совсем в реальном времени это вычитать (100 раз в цикле, извлекая только бит относящийся к нужному микрофону), транформировать PDM в PCM и передать в CPU. На эту вторую фазу отводится 230 мс. Прочитать нужно 25 млн. слов, т.е. где-то 100 млн. слов в секунду, т.е. задержка 10нс. Это самое сложное (впрочем легко поделить на N если набрать из памяти 64-разрядный массив, например). Времени на обработку в CPU не нужно, обработка может происходить параллельно, в момент записи следующего кадра.
[ZX]
 )
)
{kind=link}